Energy trading (and trading in general) is heavily rooted in the consumption of external data feeds. In a traditional trading front office, most of the trading tools for executing trades are actually produced by the execution venues themselves. Traders can submit bids and offers on clients such as WebICE and CME Direct and while these clients do provide some information regarding the trades executed and market data, the actual data is ingested using the execution venues data feeds. These data feeds are typically broken into three separate feeds: trade capture, order routing and market data. The trade capture feed is only the executed trades by the counterparty. The order routing allows counterparties to submit bids and offers electronically as well as receiving execution reports. Finally, the market data feed is just pricing data but it reflects all the public pricing data generally available including bids, offers, trades and volumes along with depth of market.
Data Consumption Pattern
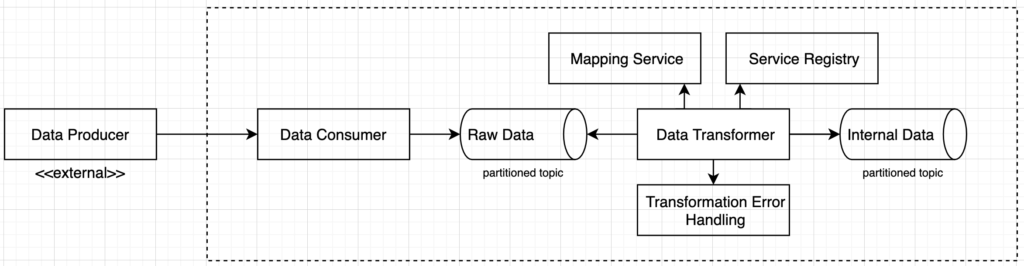
- Data Producer – this represents the external data feed from the execution venue. These are typically socket based TCP or UDP data streams based on the FIX protocol but can vary based on the use case. For example, the CME Market Data Platform feed is based on Simple Binary Encoded (SBE) FIX messages which give it a performance advantage necessary in disseminating market data, which may be millisecond latency sensitive in extreme cases.
- Data Consumer – the consumer should be focused on two priorities: establishing and maintaining proper connectivity with the producer and getting the data off the wire quickly. The consumer is typically purpose built for single data feed from a single execution venue, because each interface may have different requirements in terms of authentication, subscribing to channels, and handling custom data structures. We want it to get connected and get the data off the wire and onto the Kafka topic quickly. This is a great use case for reactive architecture.
- There may be a temptation to start doing transformation logic in the data consumer. Any additional logic can create latency in message processing which could create backpressure on the TCP/UDP sockets. The goal is to turn the single inbound pipe into a partitioned and horizontally scalable prior to performing any latency inducing business or transformation logic.
- The raw data topic will also provide a nice data set for use in lower level environments for testing the entire workflow. If we lose the raw messages, then developers will be required to manually generate mock data feeds. This saves developer time and eliminates any issues with human error in reproducing production-like data quality.
- Based on the throughput needs of the feed, the raw data topic should be partitioned to allow for the horizontal scalability needed by the data transformer.
- Data Transformer – the transformation logic resides here and is the most complicated piece of the flow. The goal of the transformer is to convert the execution venue data structures into a set of common data structures to be consumed by all the downstream applications. Similar to the data consumer, this application will be purpose built for a single data feed from a single execution venue because it will need explicit knowledge of the feed’s custom data structures. The data transformer should be horizontally scaled to the partitions available in the raw data feed topic.
- Service Registry – the first responsibility will be to convert the data structures. By using a centralized schema registry for all the internal data structures, the organization can utilize and promote clear schema changes to the enterprise in an organized manner. The Red Hat Service Registry product supports a myriad of artifact types, including Apache Avro, JSON and Protobuf schemas.
- Mapping Service – the data transformer will be required to not only convert data from one structure to another, but it will also require data mappings. These are two typically composite key-value lookups where the inbound data field combined with data source information can be used to swap values with internally defined values. For example, the executing trader’s user id from the execution venue will probably not match the internal trader user id on trade capture reports. The mapping service should allow for the transformer to pass the execution venue name, the execution venue’s data field name and the execution venue’s data value to the mapping service and receive a mapped value in return to be used in the internal data structure.
- The mapping service will need to be very fast. It is highly recommended to use an in-memory data grid, such as Red Hat Data Grid, to boost the performance on the lookups. The RHDG Hot Rod client is highly configurable and can support near caching in the client itself to
- Transformation Error Handling – the data transformer will have errors. Messages will arrive with unforeseen data structure issues or with data field values that are missing mappings. The transformation error handler should serve as a waiting “queue” for these issues and should provide notifications to the appropriate support teams to provide the remediation.
- Remember, the data doesn’t need to be copied. Kafka topics are persistent. The transformation error handler only needs to know the message’s topic, partition and offset and the data can be retrieved directly. The only trick that will need to be implemented is how to reply that message in the data transformer after the data remediation has been completed by support.
Pattern at Scale

The pattern ends up producing three key characteristics of the system. First, the actual systems which provide value to the business around managing their position, risk, compliance and P&L can all be built on a single unified set of expected data structures. This will greatly simplify the development efforts related to data adaptation and will allow for greater flexibility when onboarding a new execution venue. Second, it creates the modularity needed to be responsive to changes from the execution venues themselves. The individual applications in the chain can be quickly adapted and they insulate the downstream system from change. Last, this pattern will scale. With the power of Kafka and the horizontal scalability of consumers to grow to partition sizing, the transformation layer, which will be most susceptible to introducing latency and therefore potential backpressure, can rely on the messaging framework for stability and performance.